The Hilarious Fragility of NLP APIs

Recently I've been working on functionality in Follow Reset that requires machine learning and natural language processing, so I've been experimenting with two well-known NLP APIs: AWS Comprehend and Google Natural Language. While my primary interest in these API's is for their custom modeling capabilities, I was curious to see what kind of quick results I could get from their basic entity recognition and categorization functionality.
The high-level product goal is simple: use Twitter bios to extract and detect high-level categorical information about people.
My main test case is the profile description of Joe Rogan, a very well-known comedian and podcaster with 4.68M Twitter followers (as of writing).
My (naive) hope was that these APIs would be able to extract from this description that this person is Joe Rogan, who is a comedian.
The results were...uh...surprising, to say the least.
😕 Initial (odd) results
I used Joe's Twitter bio as the input into both APIs:
Stand up comic/mixed martial arts fanatic/psychedelic adventurer Host of The Joe Rogan Experience #FreakParty http://www.facebook.com/JOEROGAN
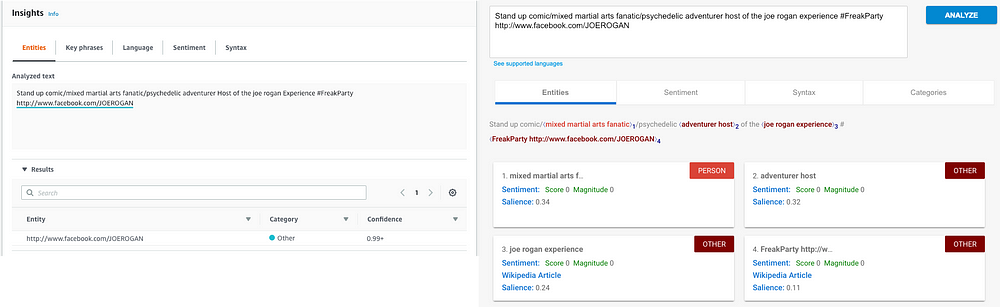
AWS Comprehend recognizes Joe Rogan as a person. Good start. AWS has a feature called key phrase extraction, that unfortunately in this case, doesn't add much context and is in general pretty useless here.
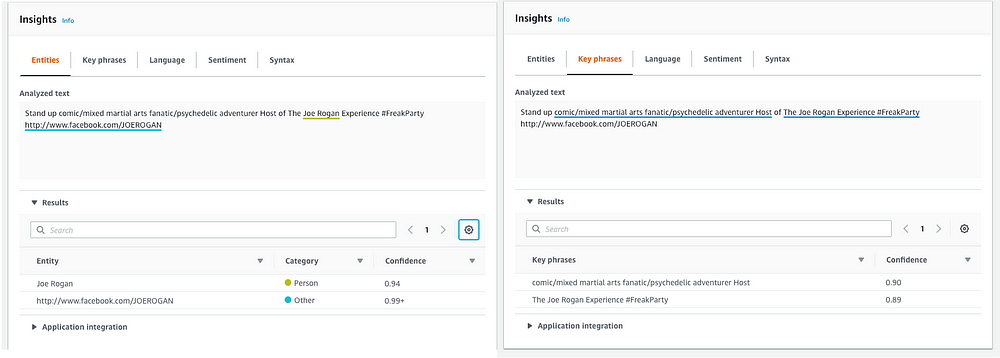
Google, on the other hand, doesn't actually recognize "Joe Rogan" as a person, though it identifies both "Host" and "mixed martial arts fanatic" as a Person entity. Odd.
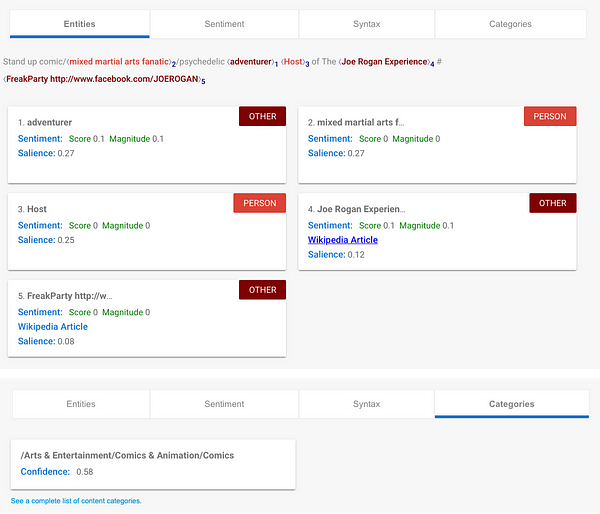
While Comprehend's entity results tend to be more factual, (Joe Rogan is a person) Google's results attempt to provide context, identifying direct contextual entities in his bio like "adventurer", as well as a Wikipedia article about the Joe Rogan Experience - his highly popular podcast - context not contained in the bio.
One thing that jumps out here is that while Google identifies categorical context -this is probably the description of a comic - it is unable to properly identify the Person entity to which the comic category refers. Considering Google's ability to detect and suggest context that is external to the input string, it's a bit of a head-scratcher that it fails to correctly identify the Person entity.
🔑 Changing the Inputs, Content is Key?
What happens if we change the name from Joe Rogan to Alex Sharp?
Here's the updated input string:
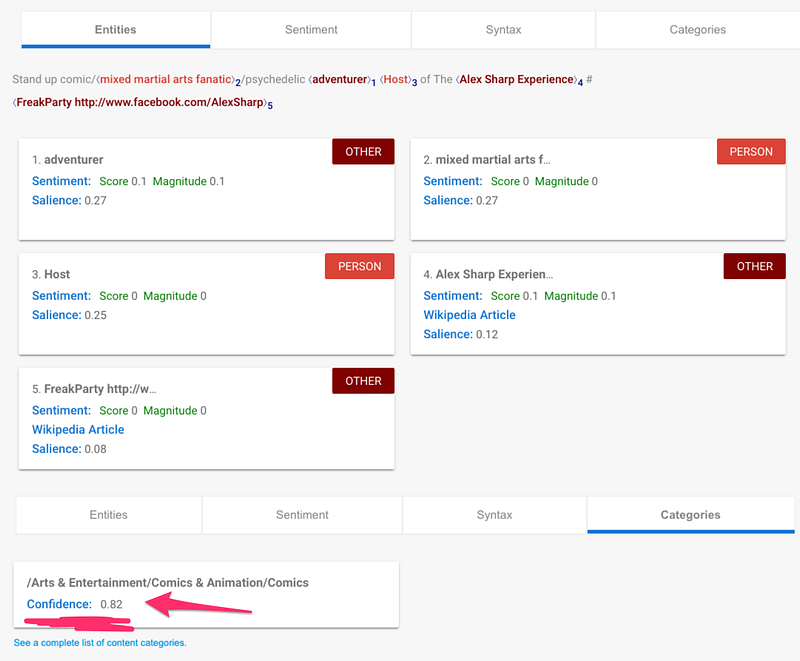
Stand up comic/mixed martial arts fanatic/psychedelic adventurer Host of The Alex Sharp Experience #FreakParty http://www.facebook.com/AlexSharp
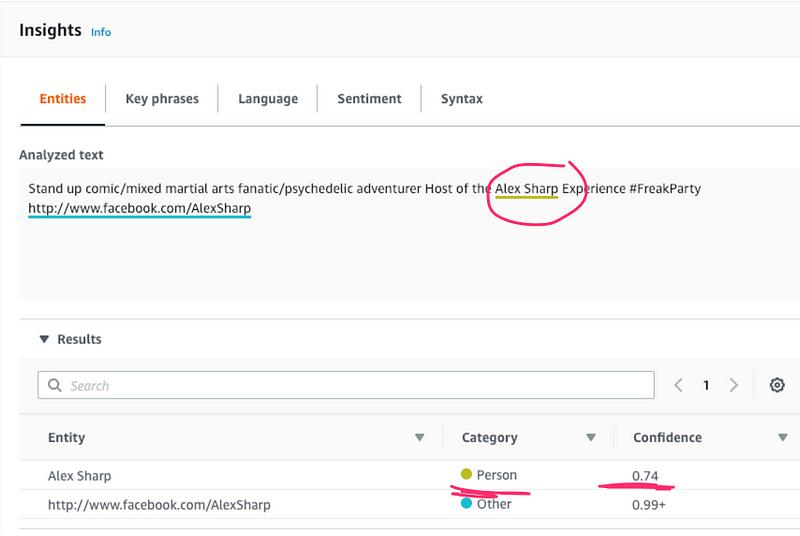
Amazon's still sees Alex Sharp as a person entity. Cool. I am that. 🙋♂️
Google's results are…unexpected. Somehow, Google is more confident that Alex Sharp is a Comic than Joe Rogan. Uh, sure 😂
🙃 joe rogan is not Joe Rogan?
What happens if you de-capitalize Joe Rogan to joe rogan? When we do this, Amazon no longer recognizes the person entity. Google still thinks we're probably talking about a comic, but not by much.
What happens if we substitute the name for a fictional character, or if we change the capitalization of some of the words around the name? Here I've changed the name from Alex Sharp to Ronald McDonald.
Both APIs seem to have a much easier time recognizing a Person entity if it's not surrounded by other capitalized words.
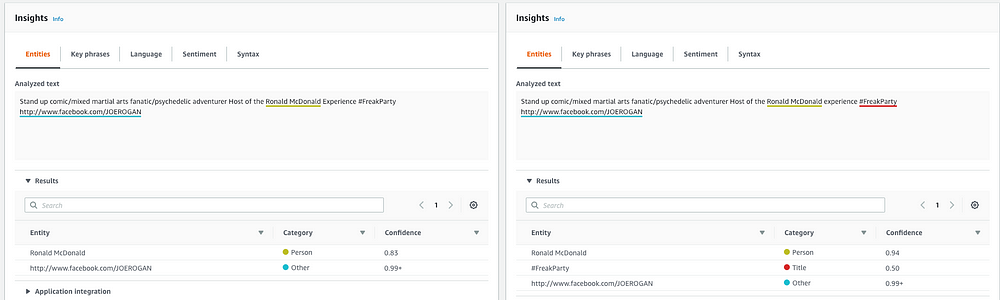
Amazon recognizes both forms but has a much higher confidence level when Ronald McDonald is not surrounded by a capitalized word.
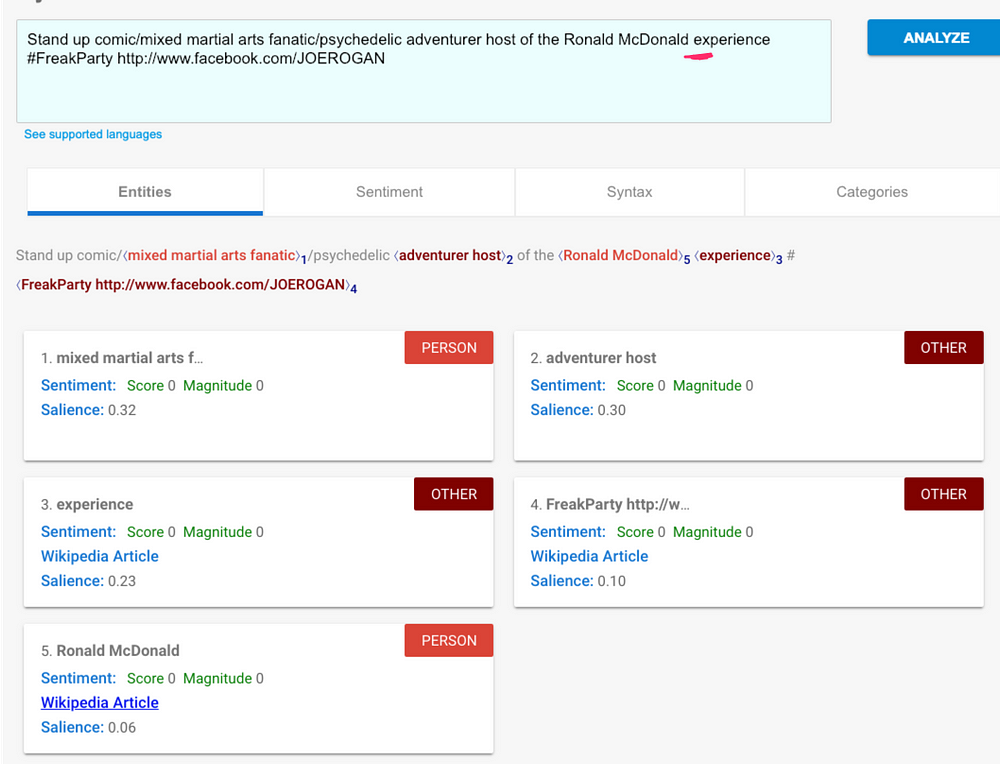
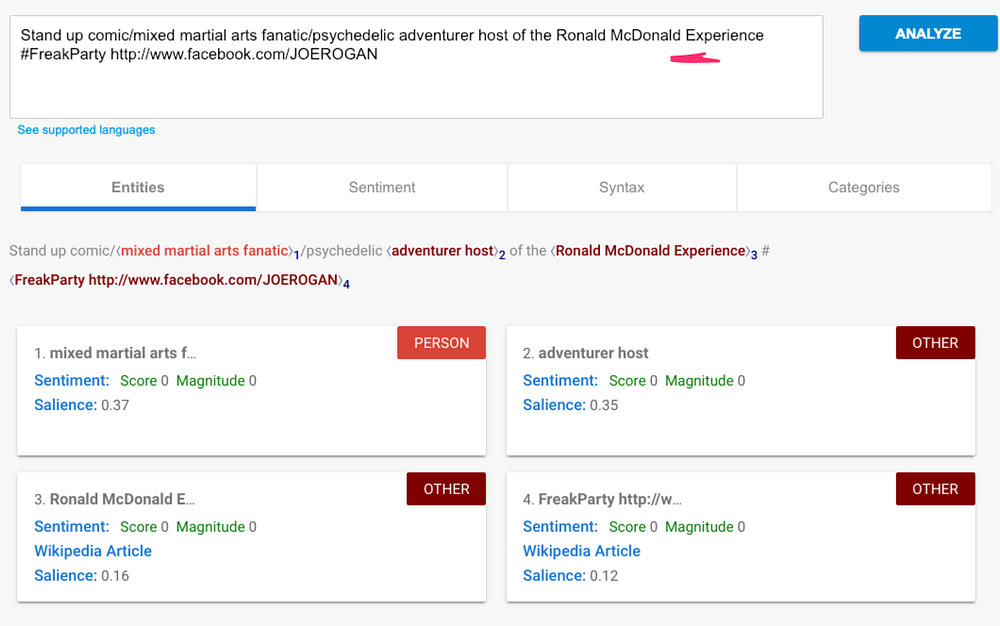
Google's results are more stark, failing to recognize a Person entity at all if the term is surrounded by other capitalized nouns: it recognizes the whole phrase Ronald McDonald Experience as "Other". It thinks it's something, but it doesn't know what.
While these results make logical sense to a layman - capitalized words are often proper nouns - it's a bit disappointing that these products rely on such basic and fragile grammar rules.
☝️Massively Unqualified Advice to Amazon & Google
It seems to me (enormous caveat: I'm a complete ML/AI amateur) that the person entity recognition issue could be improved by identifying names based on whether they match (or don't match) dictionary words. Neither the words joe or rogan are dictionary words, so can we reasonably assume, with mild confidence, that paired together, joe rogan might be someone's name? I dunno, I'm way beyond swimming in the deep end of a pool I barely understand 🤷🏻♂️.
🧙♀️🚫🦄 No Magic Here
As we can see, these APIs can be incredibly fragile, often reacting in odd and unexpected ways to tiny changes in input.
They seem to operate around fairly rudimentary grammatical "rules" - proper nouns must be capitalized, proper nouns must exist on their own - which are in many cases incredibly fragile, especially considering that many of us aren't exactly writing on the internet and social media in academically sanctioned grammar. Change an uppercase letter to lowercase and the whole thing breaks, and poor Joe Rogan is robbed of his personhood. Sad. 😟

Outside of this largely underwhelming but head-scratching exercise in curiosity, there is some truly mind-blowing work happening in deep learning powered machine learning and NLP. Unfortunately, AWS Comprehend and Google AutoML feel more like the training wheels version of a technology that can literally type words before we've thought of them, beat humans at complex strategy games, drive cars, and more. Unfortunately, these APIs are pretty underwhelming for anything other than basic grammar categorization and sentiment analysis (not covered here).
🙏 Thanks for reading. If you're interested in learning more about the product that inspired the work for this post, check out and subscribe to Follow Reset, which will soon make it very easy to clean up your Twitter feed.